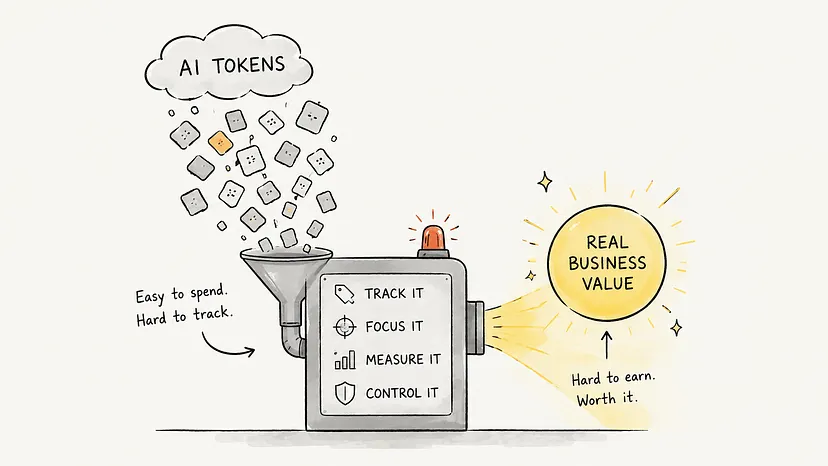
The AI Margin Crisis: How We Slashed Our Inference Costs by 80%

The Gold Rush phase of Generative AI is moving into an era of efficiency. At the start of 2023, most tech startups just wanted to get a prompt to work. Now that we are using these Generative AI applications with thousands of users, the conversation has changed from “Can Generative AI do this?” to “How much does Generative AI cost per request?”
The cost of using a Generative AI model, which is the price paid to a provider like OpenAI, Anthropic, or Google for every token generated, can become a big problem for startups. It can be more expensive than hosting. If your costs are not reasonable, your Generative AI feature is not a product; it is a liability.
We believe that inference economics is very important for AI engineers in 2024. By using a layered optimization strategy, we have seen teams reduce their spend by up to 80% without losing output quality. Here is a plan to master your Generative AI margins.
1. The Multi-Model Routing Strategy
Startups often make the mistake of using one Generative AI model for every task. Using GPT-4 or Claude for everything is like hiring a PhD to answer a customer service question. This is not an efficient use of Generative AI.
To save costs, you must categorize your tasks by complexity. We recommend a three-level architecture:
- Tier 1: Complex tasks like reasoning, multi-step logic, and creative writing. Use advanced Generative AI models here.
- Tier 2: Medium complexity tasks like summarization, extraction, or sentiment analysis. Use models like Flash or Haiku.
- Tier 3: Tasks like classification, formatting, or data cleaning. Use small or open-source models like Llama 3.
Using a model router, your application can select the appropriate model based on user intent. Sending 60% of your traffic to smaller models can reduce your bill by half.
2. The Art of Prompt Pruning and Compression
Tokens are what you pay for when using large language models. You are likely spending too much on unnecessary words. Long prompts and repetitive context windows can increase costs. These models do not need that much text to understand your intent.
Avoid excessive wording in prompts, as many developers include long examples. While effective, they also increase costs. We suggest fine-tuning models for specific tasks. By training on a few hundred examples, you can often remove long instructions, reducing input tokens by up to 70%.
Use context caching if your application repeatedly sends the same context. This allows the provider to reuse processed tokens at a lower price, which helps reduce costs.
3. Optimizing RAG: Quality Over Quantity
RAG is the standard for building AI on top of data, but it is often implemented inefficiently. Most systems retrieve too much data, which increases costs.
To reduce costs, focus on reranking:
- Retrieve potential document chunks using search. This is a cost-effective way to find relevant data.
- Use a model to identify the most relevant chunks.
- Only send those selected chunks to the large language model.
This approach ensures you are not paying for the model to process unnecessary data. Caching can also help bypass the model for repeated queries.
4. Output Token Control
Input tokens are relatively cheap. Output tokens are expensive. Large language models can be too verbose, adding unnecessary words that increase costs.
You can control this through output engineering:
- Set a limit on the number of tokens the model can generate.
- Use JSON mode and schemas to enforce structured outputs.
- Use stop sequences to cut off generation once the required information is provided.
5. The Shift to Open Source and Self-Hosting
For growing startups, an API-first approach can become expensive. At scale, hosting your own models can be more cost-effective than paying per token.
Deploying models like Llama 3 or Mistral on your own infrastructure allows for:
- Cost control: You pay for hardware instead of tokens, making expenses predictable.
- Quantization: Run efficient models on limited hardware without major loss in accuracy.
The Next Value Exchange
In the AI startup landscape, winners will be those with strong margins. Reducing inference costs by 80% is not just about saving money; it gives you the flexibility to experiment, lower pricing, and stay competitive.
Generative AI is powerful, but it can be expensive. By optimizing your margins, you make it both efficient and scalable.
We recommend starting with a token audit. Identify where your tokens are being spent and begin optimizing. The goal is to make your AI as efficient as it is intelligent. It takes effort, but the results are worth it.
Looking to build a high-performing remote tech team?
Check out MyNextDeveloper, a platform where you can find the top 3% of software engineers who are deeply passionate about innovation. Our on-demand, dedicated, and thorough software talent solutions provide a comprehensive solution for all your software requirements.
Visit our website to explore how we can assist you in assembling your perfect team.