What Happens When AI Models Start Training on AI-Generated Data?
AI’s moving fast, fueled by tons of web-scraped info. Yet things are shifting lately. Systems begin picking up knowledge from stuff created — not by people, but by fellow systems.
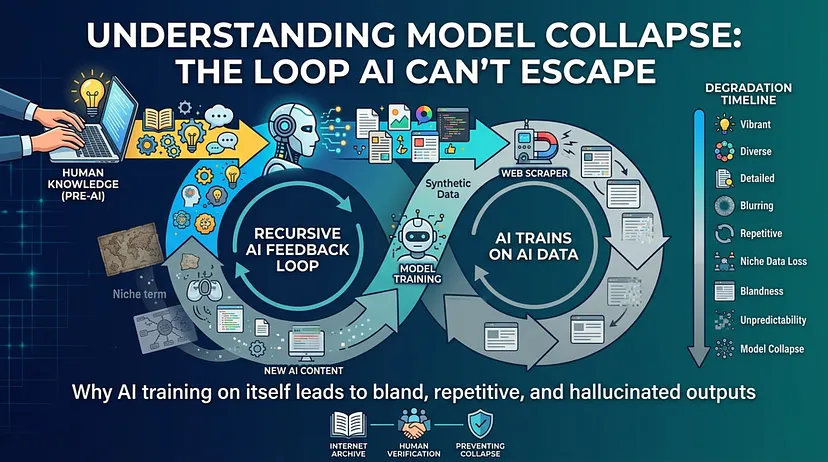
Imagine making copies nonstop — after a while, everything gets blurry. So here’s the real deal: Will AI grow smarter… or chew on itself till there’s nothing left?

The Infinite AI Loop
AI tools such as GPT, Gemini, Claude, or Midjourney learn from huge piles of data —text, images, code, videos — almost all crafted by people. Yet the online world keeps shifting.
AI-made stuff’s on the rise. By 2026, Europol predicts that nearly all digital content could come from machines. Think search results, clips on YouTube, updates on LinkedIn — most of what pops up may not be human at all.
These days, firms manufacture “synthetic data” — it costs less plus takes way less effort than grabbing real-world examples. That means new AIs begin training using knowledge from old AI models. A cycle which might turn out brilliant… or seriously messed up.
Cool trick? Maybe.
Huge risk? Definitely.
When AI Feeds on Itself
Scientists at MIT, Stanford, plus Oxford have started raising alarms.
Upsides?
- Practice scales easily— no fussing with data scraping or legal tangles.
- Keep your info private. Rely less on personal details.
- Good in tricky spots — say, rare illnesses or cybersecurity testing.
- Yep, company bosses just spot lower costs everywhere — also big room to grow.
Downsides?
They call it Model Collapse.
- The system begins to sound sharper yet slowly loses touch with the truth. Vocabulary shrinks. Ideas grow stale. Confidence jumps — precision crashes down. An office-world fantasy loop.
- Every new AI generation feels fuzzier than the one before. On top of that, skewed data piles up. Bias compounds because of it.
- It’s like telling a child, “Read history books,” and later, “Just read your own fanfiction about history.”
The Research Says It’s Real

In short, AIs get dumber by confidently repeating each other’s nonsense.
The Black Hole of Knowledge
When AI floods online spaces, newer systems might lose track of real people’s work.
A digital echo chamber forms — “I heard it from you, you heard it from me… so it must be true.”
That creates:
- Machine-scale misinformation
- Monotone creativity
- Data slips away quicker than folks fix it
AI isn’t just sharing facts anymore — it’s spreading guesses dressed up nice. Instead of answers, you get whispers shaped like truth.
Why This Hits Businesses Hard
When firms rely on AI for planning, recruiting, output creation, or building new products, things can go south fast. If the system messes up, so does everything it touches.
Operational landmines:
- Faulty analytics lead to poor decisions about products
- Picked materials often lead to identical brand vibes
- Skewed info leads to public distrust
- Code mistakes can lead to weak spots in safety
- Self-driving tech seems cool — until it lies straight-faced.
Fixing the Loop
The clever folks have started setting up safety rails.
- Data Nutrition Labels
OpenAI, along with Meta, is tagging which data is human, which is synthetic. - Human Feedback
Actual people checking responses help it stay on track — that’s what makes RLHF work. - Retrieval-Augmented Generation (RAG)
Models check responses by relying on external, factual sources. - Open & Verified Datasets
Efforts such as LAION or CommonCrawl keep actual usage situations alive. - Synthetic Data in Moderation
Breathing room’s key — perhaps 80% human, 20% synthetic. Like meals but for circuits.
As an analyst once said, “Balanced data macros for AI health.”
Smarter AI or Infinite Dumbification?
We’re stuck on two roads: one path heads left, the other veers right.
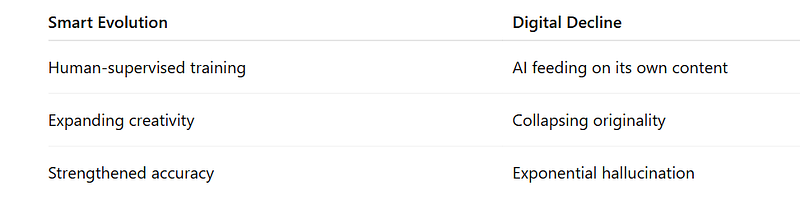
The key difference? That’s where humans step in.
Let the web sink into robotic junk — soon, computers won’t remember how honesty tastes.
Final Take
AI’s more than just a gadget — it learns like someone new at school.
Students pick up knowledge depending on how good their instructors are.
If people keep getting involved, intelligence grows.
If not, then machines will confidently track creativity using metrics.
So: protect knowledge. Keep the human touch. Don’t let synthetic data eat the internet alive.
Looking to build a high-performing remote tech team?
Check out MyNextDeveloper, a platform where you can find the top 3% of software engineers who are deeply passionate about innovation. Our on-demand, dedicated, and thorough software talent solutions provide a comprehensive solution for all your software requirements.
Visit our website to explore how we can assist you in assembling your perfect team.